





大家好,我是peachesTao,今天给大家分享一篇关于mysql优化器的文章,在正式进入今天的主题之前先抛出几个问题:
- mysql 对我们写的sql语句做了哪些优化?优化后的语句我们如何得知?
- 为什么我的字段明明加了索引最后还是全表扫界?
- 一个字段存在于多个索引中,为什么最后选择了索引A,而不是B?
如果你也有上面的疑问,那么你算是来对了,通过这篇文章,我将会为大家解开谜底。
我们先准备一下本篇文章要用到的表结构(注意:本文中所有的数据均基于mac mysql 8.0.12)users表,以下是建表脚本
create table `users` (
`uid` int(11) not null default '0',
`id` int(11) not null auto_increment,
`name` varchar(255) not null,
`age` int(11) not null,
primary key (`id`),
key `index_uid` (`uid`) using btree,
key `index_name` (`name`) using btree,
key `index_age` (`age`) using btree
) engine=InnoDB auto_increment=356 default charset=utf8mb4 collate=utf8mb4_0900_ai_ci; ?初始化数据
create procedure initData()
begin
declare count int default 1;
while count <=100 DO
insert into users (uid,`name`,age) values (count,concat('学生',cast(count as char(20))),count);
set count=count +1;
end while;
end
call initData();上面我们建了一张users表,并写入了100个用户信息
我们看一个例子:查询年龄大于20岁的人,这里我们加上explain命令分析执行情况
explain
select * from users where age>=20;结果如下:
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | index_age | NULL | NULL | NULL | 100 | 81.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+可以看到可选择的索引有index_age,但并没有使用它,通过type='ALL'可以看出最终选择的是全表扫描,问题来了:“明明在age字段创建了索引为什么不用呢?”,在回答这个问题之前我们先了解一下mysql服务器的架构
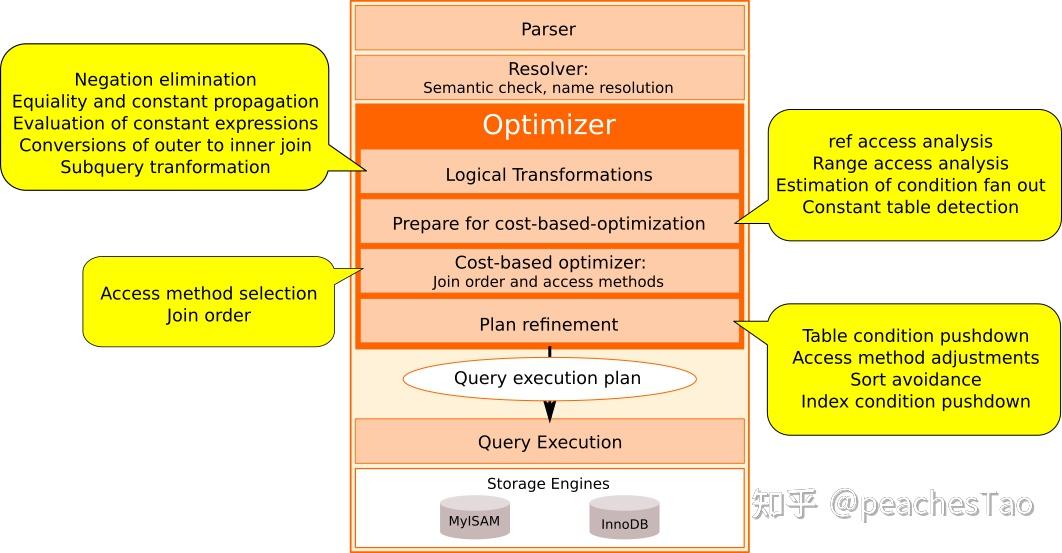
mysql服务器共分为下面5个部分:
- Parser(分词操作)
我们在客户端发送给 MySQL 的 SQL 语句实质上就是一个字符串,MySQL 需要将其拆分成一个个的分词(语法树)并进行识别,例如识别“SELECT”、“UPDATE”等关键字,将 t1 识别为一张表,将 id 识别为一列等 - Resolver(语法分析)
拿到词法分析的结果,并根据语法规则判断 SQL 语句是否合法,不合法则直接退出执行,并将错误信息告知客户端 - Optimizer(优化器)
到这一步已经拿到了合法的sql语句了,但mysql并不认为我们写的语句是最优的,会将它转化它认为最优的语句以及选择最优的执行方案,比如调整join语句中表的连接顺序、去除无效的条件、当表中有多个索引时决定选择哪一个等等。 - Query Execution(查询执行)
经过上一步优化,已经选出了最优的查询方案,这一步就是调用存储引擎的api接口获取数据,当执行完成后将数据返回给客户端 - Storage Engines(存储引擎)
存储引擎层,包含Innodb和MyISAM引擎
介绍完服务器的架构,现在知道我们写的sql语句的优化和选出最优执行方案都是通过优化器完成的,虽然可以通过explain命令知道优化器优化后选择的结果,但并不能看出:
- 优化器是基于什么选出最优方案的?
- 为什么备用方案没有被选择,难道是因为成本更高?
以上答案可以通过optimizer_trace告诉你,它有神奇的功效,可以提供优化器分析和决策的详细过程,下面介绍optimizer_trace使用
这一部分内容比较长,属于偏文档型的内容,mysql官方文档只告诉了你怎么用,没有介绍各个字段的意思,所以这里就列出来了,希望大家耐心读完
Optimizer Trace 是MySQL 5.6.3里新加的一个特性,可以把MySQL Optimizer的决策和执行过程输出成文本,结果为JSON格式,兼顾了程序分析和阅读的便利。
optimizer_trace默认是关闭的,需要开启后才能使用,以下为开始和使用方法
1、set optimizer_trace="enabled=on"; -- 开启optimizer_trace
2、select * from users where age>=20;-- 要分析的sql语句,可以有多个
3、select * FROM information_schema.optimizer_trace;-- 查询优化跟踪过程
4、set optimizer_trace="enabled=off"; -- 关闭optimizer_trace注意,set optimizer_trace="enabled=on"只会在当前连接回话生效,如果要所有连接生效则需要在前面加上global选项,即:
set global optimizer_trace="enabled=on";下面是下优化跟踪输出结果:

- QUERY
原始查询语句 - TRACE
存储的是优化跟踪的数据,以json格式存储,一般将其复制出来放到专门的json编辑器中阅读,如果跟踪数据很大的话复制会卡顿,甚至导致mysql客户端软件崩溃,建议将TRACE列导出到本地文件来分析,在后面增加into outfile命令即可:
select trace from information_schema.optimizer_trace into outfile '/data/mysql/trace_data.json' fields escaped by ''fields escaped by ''的意思是取消json字符串中的转义字符'\\'
- MISSING_BYTES_BEYOND_MAX_MEM_SIZE
丢失多少字节数据,如果该值大于0,表示有跟踪数据丢失,这时就需要增加optimizer-trace-max-mem-size变量的值(该变量下面会介绍)
几个有用的系统变量
- optimizer_trace_max_mem_size
显示的优化器跟踪数据的最大数量,单位为字节,默认为1048576,如果跟踪的数据大于该值数据将截断,可通过命令:set optimizer-trace-max-mem-size=2048576 修改 - optimizer_trace_limit
显示优化器跟踪的个数,默认为1,配合optimizer_trace_offset一起工作 - optimizer_trace_offset
跟踪偏移量,默认为-1。假定值为n,如果n>=0,表示从正序从第n+1个sql语句开始跟踪,如果n<0,表示倒叙从第n个跟踪开始 - end_markers_in_json
输出的json字符串是否在每个字段结束后带上标注,这在json字符串很长时非常有用,大大增加了可读性,默认为“off”,可通过set end_markers_in_json='on'开启,效果如下:
"join_preparation":{
"select#": 1,
"steps":[
{
"expanded_query": "/* select#1 */ select `users`.`uid` AS `uid`,`users`.`id` AS `id`,`users`.`name` AS `name`,`users`.`age` AS `age` from `users` where ((`users`.`age` >=20) and (1=1))"
}
]/* steps */
}/* join_preparation */
optimizer_trace_offset和optimizer_trace_limit有点像分页查询中的offset和limit,我们举一个一次性跟踪两条sql语句的例子来展示一下它们的作用
select * from users where age>=20;
select * from class where name='暑期班';- optimizer_trace_offset=-1
optimizer_trace_limit=1,只显示倒序第1个sql语句的跟踪信息,即class表的跟踪信息
optimizer_trace_offset=2,显示users表和class表的跟踪信息 - optimizer_trace_offset=0
optimizer_trace_limit=1,显示从正序第1个sql语句开始共1个跟踪信息,即:users表的跟踪信息,optimizer_trace_offset=2,显示从正序第1个sql语句开始共2个跟踪信息,即:users表和class表的跟踪信息 - optimizer_trace_offset=1
optimizer_trace_limit=1,显示从正序第2个sql语句开始共1个跟踪信息,即:class表的跟踪信息,optimizer_trace_offset=2,显示从正序第2个sql语句开始共2个跟踪信息,即:class表的跟踪信息
这个过程展示了准备阶段的执行过程
"join_preparation":{
"select#": 1,
"steps":[
{
-- 对比下原sql语句,这里将要查询的列表全部列出来了
"expanded_query": "/* select#1 */ select `users`.`uid` AS `uid`,`users`.`id` AS `id`,`users`.`name` AS `name`,`users`.`age` AS `age` from `users` where (`users`.`age` >=20)"
}
]
}
}这一段展示了优化以及最优执行方案的决策过程,是分析optimizer_trace的重点内容,共分为9个子过程,这一段内容很长,而且会随着sql语句的复杂性的增加而增加,下面我们来一一介绍
条件优化,对where或者having条件进行优化
"condition_processing":{
"condition": "WHERE",
"original_condition": "((`users`.`age` >=20) and (1=1))",
"steps":[{
"transformation": "equality_propagation",
"resulting_condition": "((`users`.`age` >=20) and (1=1))"
},
{
"transformation": "constant_propagation",
"resulting_condition": "((`users`.`age` >=20) and (1=1))"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`users`.`age` >=20)"
}
]
}condition:条件,优化的对象,值为:“where”或者“having"
original_condition:原始条件
resulting_condition:优化之后的条件
这里有三个优化:
- equality_propagation 等值传播
- constant_propagation 常量传播
- trivial_condition_removal 无效条件移除 如条件中有“1=1”之类的恒等式将会被移除
替代生成的列
"substitute_generated_columns":{}分析表之间的依赖关系
"table_dependencies":[{
"table": "`users`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits":[]
}]列出所有可用的ref类型的索引
估算各种执行计划需要扫描的记录数和成本,这一步是优化器的核心部分,这一步的分析数据会作为选出最佳执行计划的依据
"rows_estimation":[{
"table": "`users`",
"range_analysis":{
"table_scan":{
"rows": 100,
"cost": 12.35
},
"potential_range_indexes":[{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "index_uid",
"usable": false,
"cause": "not_applicable"
},
{
"index": "index_name",
"usable": false,
"cause": "not_applicable"
},
{
"index": "index_age",
"usable": true,
"key_parts":[
"age",
"id"
]
}
],
"setup_range_conditions":[],
"group_index_range":{
"chosen": false,
"cause": "not_group_by_or_distinct"
},
"analyzing_range_alternatives":{
"range_scan_alternatives":[{
"index": "index_age",
"ranges":[
"20 <=age"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 81,
"cost": 90.11,
"chosen": false,
"cause": "cost"
}],
"analyzing_roworder_intersect":{
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
}]- table 分析的表名
- range_analysis 扫描范围分析
1、table_scan 全表扫描
2、range_scan_alternatives 索引扫描分析 - index:索引名
- ranges:range扫描的条件范围
- index_dives_for_eq_ranges:是否使用了index
dive,该值会被参数eq_range_index_dive_limit变量值影响。 - rowid_ordered:该range扫描的结果集是否根据PK值进行排序
- using_mrr:是否使用了mrr
- index_only:表示是否使用了覆盖索引
- rows:扫描的行数
- cost:索引的使用成本
- chosen:表示是否使用了该索引
- index 索引名称
- usable 是否使用
- cause 没有使用的原因
- key_parts 如果使用了该索引,列出索引中可用的字段
- rows 扫描总行数
- cost 需要的总成本
3、analyzing_roworder_intersect 分析是否使用了索引合并(index merge)
4、potential_range_indexes 列出表中所有的索引
5、setup_range_conditions 如果有可下推的条件,则带条件考虑范围查询
6、group_index_range 分组索引分析,分析group by和distinct使用索引的情况
综合考虑各个计划,并选出最终的执行计划
"considered_execution_plans":[{
"plan_prefix":[],
"table": "`users`",
"best_access_path":{
"considered_access_paths":[{
"rows_to_scan": 100,
"access_type": "scan",
"resulting_rows": 100,
"cost": 10.25,
"chosen": true
}]
},
"condition_filtering_pct": 100,
"rows_for_plan": 100,
"cost_for_plan": 10.25,
"chosen": true
}]- plan_prefix:当前计划的前置执行计划。
- table:涉及的表名,如果有别名,也会展示出来
- best_access_path:通过对比considered_access_paths,选择一个最优的访问路径
- considered_access_paths:当前考虑的访问路径
- access_type:使用索引的方式,可参考explain中的
- type字段
- index:索引
- rows:行数
- cost:开销
- chosen:是否选用这种执行路径
- condition_filtering_pct:类似于explain的filtered列,是一个估算值
- rows_for_plan:执行计划最终的扫描行数
- cost_for_plan:执行计划的代价
- chosen:是否选择了该执行计划
经过上面considered_execution_plans这一步,已经选出了最佳执行计划,这一步会根据这个计划执行情况在表上附加一些条件
"attaching_conditions_to_tables":{
"original_condition": "(`users`.`age` >=20)",
"attached_conditions_computation":[],
"attached_conditions_summary":[{
"table": "`users`",
"attached": "(`users`.`age` >=20)"
}]
}精炼执行计划
"refine_plan":[{
"table": "`users`"
}]执行计划,优化跟踪的最后一步,执行选出的计划,调用存储引擎层api
"join_execution":{
"select#": 1,
"steps":[]
}给能坚持阅读到这里的你们点个赞,有了上面的铺垫下面的内容会很轻松
经过上面对optimizer_trace的介绍,我们知道优化器是根据成本来决定选择哪一个计划的,我们回过头来分析文章开头的例子。
直接看最核心的rows_estimation这一步的跟踪数据:
/*全表扫描成本分析*/
"table_scan":{
"rows": 100,
"cost": 11
}
/*索引成本分析*/
"range_scan_alternatives":[{
"index": "index_age",
"ranges":[
"20 <=age"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 81,
"cost": 90.11,
"chosen": false,
"cause": "cost"
}]
/*最佳执行计划*/
"best_access_path":{
"considered_access_paths":[{
"rows_to_scan": 100,
"access_type": "scan",
"resulting_rows": 100,
"cost": 11,
"chosen": true
}]
}从上面分析中可以看出:
- 全表扫描
共扫描100行记录,成本为:11 - 使用index_age索引
共扫描81行记录,成本为:90.11 - 最好的执行计划
全表扫描,索引计划落选的原因是成本(cause:"cost")
虽然使用索引需要扫描的行数比全表扫描要少,但需要回表,基于成本优化器选择了全表扫描,那么优化器是如何计算成本的?这其实跟优化器的成本计算模型有关,接下来我们就来介绍它
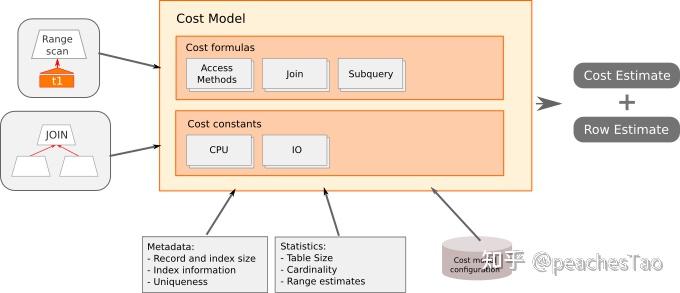
优化器决定如何执行查询的方式是基于一种称为基于成本的优化的方法。这个过程的简化如下:
- 为每个操作分配一个成本
- 评估每个可能的计划需要多少次操作
- 将各个操作成本相加
- 选择总成本最低的计划
为什么是简化的?因为优化器不会分析每种可能的执行计划的成本,只会从中选出那些很有可能成为最优的计划,想象一下,假如有5张表关联查询,每张表有5个索引,那么共有 5! * 5!=14400种可能的执行计划,如果优化器都逐个分析,很有可能分析所耗费的时间都比sql语句执行的时间长,这样的分析就失去了它的价值。
正因为如此,优化器选择的计划不是每次都是最优的,如果你能明确知道某种计划是最优的,那么你可以强制执行那个计划,比如:明确知道用索引index_a是最快的,那么你可以使用force index('index_a')强制优化器执行
每种方案的执行成本实际上由CPU成本和IO成本两部分组成的
- CPU成本
数据的读取、比较、过滤、排序等这些操作所耗费的时间成本 - IO成本
数据从硬盘加载到内存所耗费的时间成本
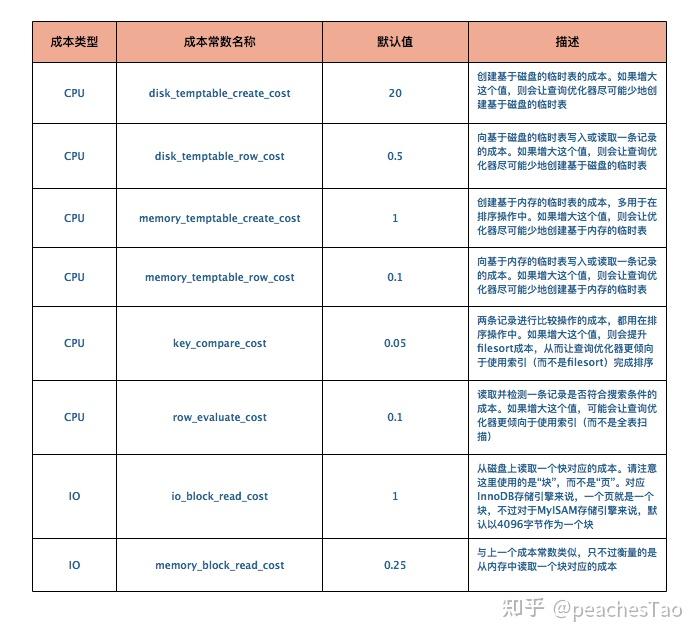
下面列出了各种操作对应的成本:
现在我们分别计算一下全表扫描和使用索引的成本
全表扫描成本
CPU成本=表中的记录数 * 读取一条记录的成本=100 * 0.1=10
IO成本=聚簇索引占用的页面数 * 访问一个页面的成本=(16384/(16 * 1024)) * 1=1
解释一下页面数是怎么计算的,每个表有一个统计数据,使用show table status命令获取
show table status like 'users'结果如下:
+-------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+--------------------+----------+----------------+---------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment |
+-------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+--------------------+----------+----------------+---------+
| users | InnoDB | 10 | Dynamic | 100 | 163 | 16384 | 0 | 49152 | 7340032 | 28637 | 2021-10-31 15:14:25 | NULL | NULL | utf8mb4_0900_ai_ci | NULL | | |
+-------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+--------------------+----------+----------------+---------+
里面有一个data_length字段,表示页面占用总内存大小,单位是字节,mysql默认一个页占用 16KB大小,所以占用的页面数=总内存大小/一个页占用内存大小
全表扫描总成本=10 + 1=11
使用索引成本
因为这个例子查询的是所有列,使用索引查到数据后还需要回表到聚簇索引再查一遍完整的数据。
CPU成本=读取索引查出的记录数 * 读取一条记录的成本=81 * 0.1=8.1
IO成本=扫描区间的个数 * 扫描区间的成本 + 回表记录数 * 访问一个页面的成本=1 * 1 + 81 * 1=1 + 81=82
注:扫描区间的成本跟访问一个页面的成本相同
使用索引的总成本=8.1 + 82 + 0.01=90.11,其中0.01是微调值,这个值直接写在源码中
需要注意的是:当索引需要回表扫描时,在各个方案比较阶段优化器是不会计算读取回表记录数据所需的CPU成本的,当在比较阶段结束选出最优方案后,如果该方案需要回表扫描,这部分成本会重新计算并加入最终成本中去,回到这个例子,如果使用索引方案被选中,则最终的CPU成本会加上:读取需要回表记录数 * 读取一条记录的成本=81 * 0.1=8.1,总成本将变成:98.21,至于为什么这样设计,我还没弄清楚。
细心的同学会发现,第一次查询和非第一次查询得到的成本值不同,非第一次的比第一次要小,原因是mysql会利用缓存来加速查询
上面只是单表查询的成本计算方法,如果是两表或多表连接查询成本的计算方式又会不同,这个后续有机会再写一遍文章介绍
有同学又会问了:上面的成本常量值可以修改吗?答案的可以的。
这些成本常量值实际上存放在mysql自带的系统数据库“mysql”中的server_cost和engine_cost表中,其中server_cost表存放CPU成本,engine_cost表存放IO成本常量
- server_cost表:
+------------------------------+------------+---------------------+---------+---------------+
| cost_name | cost_value | last_update | comment | default_value |
+------------------------------+------------+---------------------+---------+---------------+
| disk_temptable_create_cost | NULL | 2021-10-30 11:54:05 | NULL | 20 |
| disk_temptable_row_cost | NULL | 2021-10-30 11:54:05 | NULL | 0.5 |
| key_compare_cost | NULL | 2021-10-30 11:54:05 | NULL | 0.05 |
| memory_temptable_create_cost | NULL | 2021-10-30 11:54:05 | NULL | 1 |
| memory_temptable_row_cost | NULL | 2021-10-30 11:54:05 | NULL | 0.1 |
| row_evaluate_cost | NULL | 2021-11-16 21:22:24 | NULL | 0.1 |
+------------------------------+------------+---------------------+---------+---------------+
- engine_cost表:
+-------------+-------------+------------------------+------------+---------------------+---------+---------------+
| engine_name | device_type | cost_name | cost_value | last_update | comment | default_value |
+-------------+-------------+------------------------+------------+---------------------+---------+---------------+
| default | 0 | io_block_read_cost | NULL | 2021-10-30 11:54:05 | NULL | 1 |
| default | 0 | memory_block_read_cost | NULL | 2021-10-30 11:54:05 | NULL | 0.25 |
+-------------+-------------+------------------------+------------+---------------------+---------+---------------+其中 default_value的值是系统默认的,不能修改,cost_value列的值我们可以修改,如果cost_value列的值不为空系统将用该值覆盖默认值,我们可以通过update语句来修改,比如将row_evaluate_cost成本值改成100
update mysql.server_cost set cost_value=100 where cost_name='row_evaluate_cost'修改完后并不能马上生效,我参考的很多资料都说执行flush optimizer_costs命令就可以生效,不过我试过不行,我是通过重启数据库实例才能生效,这个可能是数据库版本的差异,大家可以自行验证。
修改row_evaluate_cost成本常量值后我们再来查看一下执行计划:
explain select*from users where age>=20;执行结果如下:
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | users | NULL | range | index_age | index_age | 4 | NULL | 81 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+可以从key="index_age"看出,这次优化器选择的方案是使用索引index_age来执行查询
从这个例子可以看出,更改成本常量值会直接影响优化器的方案选择,所以一定要慎重,没有特殊原因建议不要修改。
我们使用explain最常用的方法是将它放在要分析的sql的前面,如果加上format=json选项会输出json格式的分析数据,包含语句执行的成本信息
explain format=json
select * from users where age>=20; 结果如下:
{
"query_block":{
"select_id": 1,
"cost_info":{
"query_cost": "11.00"
},
"table":{
"table_name": "users",
"access_type": "ALL",
"possible_keys":[
"index_age"
],
"rows_examined_per_scan": 100,
"rows_produced_per_join": 81,
"filtered": "81.00",
"cost_info":{
"read_cost": "2.90",
"eval_cost": "8.10",
"prefix_cost": "11.00",
"data_read_per_join": "82K"
},
"used_columns":[
"uid",
"id",
"name",
"age"
],
"attached_condition": "(`peachestao`.`users`.`age` >=20)"
}
}
}
加上该选项会额外的增加成本信息,包含
- query_cost
总查询成本 - read_cost
IO成本+检测rows * (1-filter)条记录的CPU成本 - eval_cost
检测rows * filter条记录的成本 - prefix_cost
单次查询users表成本,等于read_cost+eval_cost
另外,explain结合show warnings语句一起使用还可以得知优化器改写后的语句(为了试验效果,条件中故意加了1=1)
explain format=json
select * from users where age>=20 and 1=1;
show warnings;输出message字段内容即为被优化器改写后的语句,如下:
/* select#1 */ select `peachestao`.`users`.`uid` AS `uid`,`peachestao`.`users`.`id` AS `id`,`peachestao`.`users`.`name` AS `name`,`peachestao`.`users`.`age` AS `age` from `peachestao`.`users` where (`peachestao`.`users`.`age` >=20)从优化后的语句可以看出,关键字“*”转换成了表中的各个列名,无效的条件“1=1”也被移除了,你可以通过它快速得知优化后的语句,当你的sql语句出现性能问题而无从下手时,它会非常有用。
比如你的sql语句中包含in子句,in前面的列名已经加了索引,运行时发现根本没有走索引,产生了性能问题,通过上面的方法可以查看改写后的语句,可能优化器将in子句改写成了exists子句,外表比内表数据大导致查询慢,这种情况将in改成join就能解决问题。
不过explain + show warnings这种查看改写后的sql语句并不等价于标准的sql语句,有些情况下并不能直接执行,它只是帮我们理解优化器是如何执行查询的参考。
- mysql是基于成本来选择最优执行方案的,哪个成本最少选哪个
- 成本由CPU成本和IO成本组成,每个成本常数值可以自己调整
- 通过开启optimizer_trace可以跟踪优化器的各个环节的分析步骤
- explain加上format=json选项后可以查看成本信息
- explain加上show warnings可以查看被改写后的语句
外国人写的一篇非官方 MySQL 8.0 优化器指南【非常赞】
mysql是怎样运行的【书籍,非常赞】




